Overview¶
ICOW and its free open source version lIteCOW provide the ability to quickly deploy and remotely call versioned machine learning models.
Inference with Collected ONNX Weights or Inference COW/ICOW for short, is a project to provide the inference functionality of machine learning models without requiring the resources or dependencies to run such models locally. In addition to the ICOW project, the lIteCOW project provides a subset of ICOW inference features to the open source community for free. These projects aim to provide these capabilities while adding as few dependencies as possible to the caller of the model and requiring minimal compute resources. Additionally these projects aim to remain small themselves so they primarily focus on providing remote use of machine learning models; features that add improvements to the way models are run, likely belong in upstream projects where they may benefit all users of the upstream project including ICOW and lIteCOW.
Architecture¶
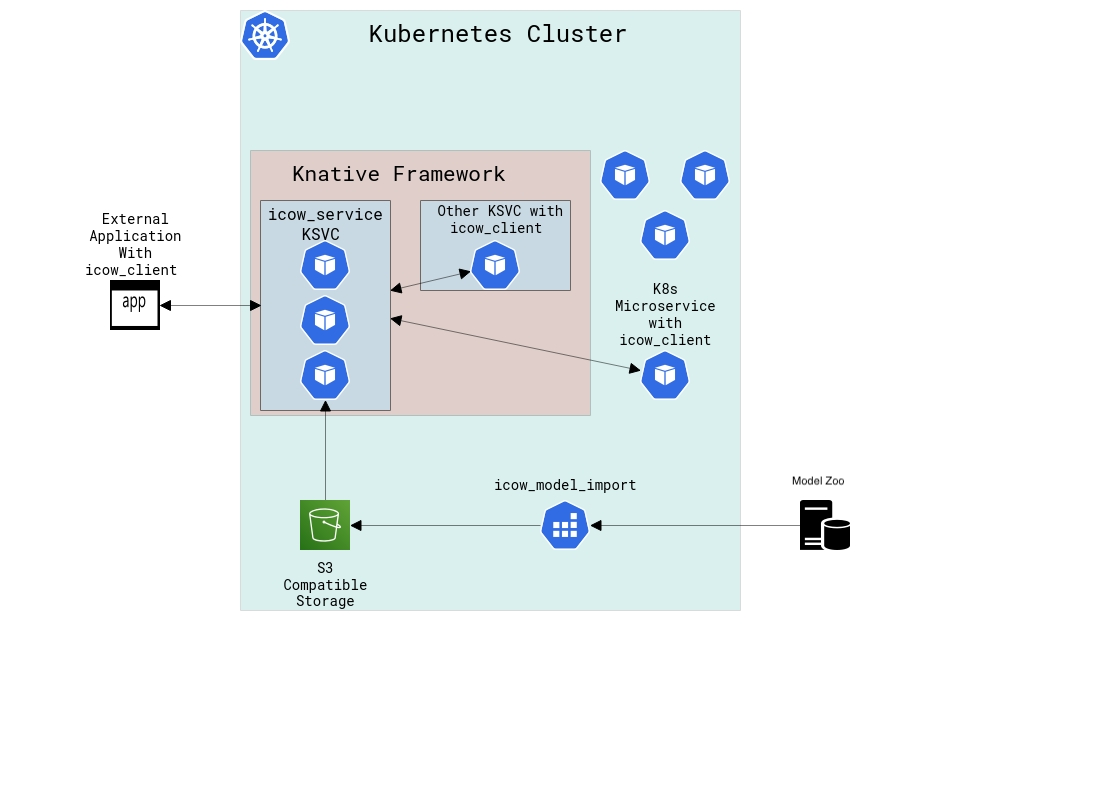
Why create/use inference COW¶
Overcome limitations of (GPU) resources when creating/deploying microservices¶
When creating a microservice which relies on machine learning model(s) and deploying it through a container orchestration tool such as kubernetes there are limitations on where/how such a microservice can run. If the microservice is allowed to run on any node in the kubernetes cluster the microservice may not be run on a node with a gpu and while it will be easier to scale, it may be overall slower since allowing the microservice to deploy on any node in kubernetes prevents the microservice from using any accelerators. If the microservice is restricted to only nodes with the appropriate gpus then the microservice will have access to a gpu for acceleration however even when not in use the microservice will have full use of the gpu and no other services will be allowed to use that gpu. This makes scaling multiple microservices that require gpus within the same cluster difficult as they will compete for resources even when they are sitting idle. To overcome this issue the actual inference work that microservices need a gpu to accelerate can be extracted and performed in a single microservice which is shared among the cluster. With the inference work extracted to ICOW/lIteCOW the microservices that rely on machine learning models will be able to freely scale on any node without worrying about access to a gpu and when those microservices are sitting idle the ICOW/lIteCOW microservice will still be available to any other microservice that needs it.
Provide a language independent way of accessing machine learning inference capabilities¶
To access machine learning inference capabilities often python is the first choice since that’s where the models were trained. However, its not only python developers that would like to incorporate machine learning inference into their applications and sometimes python isn’t well suited to the task at hand. To tackle this issue it would be nice to have a language independent definition of communication with machine learning models. While ICOW/lIteCOW implement their servers in python and provide reference client implementations in python, they define their services and requests with an Interface Definition Language protobuf and communicate to clients through the common protocol gRPC for remote procedure calls. If another client implementation becomes required the protobuf file which describes the communication can be used to generate a client in any language supported by the Protocol Compiler protoc.
Provide the ability to remotely access and use inference models as services with acceleration¶
To make use of many machine learning models currently requires the direct import and use of the machine learning libraries used to train them. While this isn’t always a problem, it requires installing machine learning libraries locally, which can add a lot to the size of a microservice deployment. This also means projects that would like to utilize inference capabilities must depend on these machine learning libraries even for a single inference call. Additionally if the project calls for accelerated inference then the local machine would need to have a gpu available for acceleration. ICOW/lIteCOW provide the use of inference models remotely potentially with gpu acceleration while only requiring that a client follow the protocol, so a machine learning library won’t be needed to call inference, and if the remote has a gpu then all the callers will benefit.